What You must Have Asked Your Teachers About Réseaux De Neurones
페이지 정보
작성자 Earnestine 작성일24-11-03 13:41 조회25회 댓글0건관련링크
본문
Introduction:
Generative Pre-Trained Transformer (GPT) is an innovative approach to natural language processing (NLP) that has gained considerable attention in recent years. GPT is built upon the Transformer model, which has demonstrated remarkable capabilities in various NLP tasks by leveraging attention mechanisms. This study report analyzes the key components, architecture, training methodology, and performance of GPT in the context of NLP.
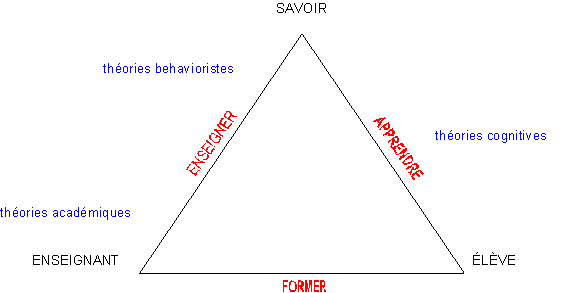 Key Components and Architecture:
Key Components and Architecture:
At the core of GPT lies the Transformer model, an attention-based architecture that relies on self-attention mechanisms to capture contextual relationships among words in a sentence. GPT uses a stack of layers where each layer comprises a multi-head self-attention mechanism followed by a feed-forward neural network. This design enables the model to effectively process sequential data by attending to important contextual information.
Training Methodology:
The GPT model is pre-trained on a large corpus of text data, typically sourced from the internet, using an unsupervised learning approach. During pre-training, the model learns to predict the next word in a sentence given the preceding context, effectively capturing the statistical and semantic information from the text. The training process uses a variant of the Transformer's attention mechanism called the masked self-attention, which ensures that the model attends only to the previous words.
Fine-Tuning and Transfer Learning:
After pre-training, GPT undergoes a fine-tuning process on specific downstream NLP tasks. This involves training the model on domain-specific labeled data to learn task-specific patterns and improve performance. The general-purpose language model pre-trained on a large dataset allows GPT to transfer its knowledge to various NLP tasks, thus reducing the need for extensive task-specific training.
Performance and Applications:
GPT has achieved state-of-the-art performance on several benchmark NLP tasks, including language generation, summarization, translation, and rnn sentiment analysis. Its ability to generate coherent and contextually appropriate text has revolutionized various applications, such as chatbots, text completion, and question-answering systems. GPT's versatility across different domains and languages has made it a preferred choice for NLP researchers and practitioners.
Limitations and Future Directions:
Despite its immense success, GPT has certain limitations. One major limitation is its potential to generate biased or untruthful content if provided with biased training data. Addressing this issue and ensuring fairness in the generated text remains a critical focus of future research. Additionally, GPT's reliance on large amounts of training data and computational resources makes it less accessible for smaller organizations or researchers with limited resources.
Conclusion:
Generative Pre-Trained Transformer (GPT) has emerged as a powerful tool for natural language processing tasks. Its ability to leverage the Transformer model's attention mechanisms and transfer learning capabilities has resulted in impressive performance across a wide range of NLP applications. With ongoing research to address limitations such as bias and improved efficiency, GPT is expected to contribute significantly to the advancement of NLP and foster new breakthroughs in artificial intelligence.
Generative Pre-Trained Transformer (GPT) is an innovative approach to natural language processing (NLP) that has gained considerable attention in recent years. GPT is built upon the Transformer model, which has demonstrated remarkable capabilities in various NLP tasks by leveraging attention mechanisms. This study report analyzes the key components, architecture, training methodology, and performance of GPT in the context of NLP.
Key Components and Architecture:At the core of GPT lies the Transformer model, an attention-based architecture that relies on self-attention mechanisms to capture contextual relationships among words in a sentence. GPT uses a stack of layers where each layer comprises a multi-head self-attention mechanism followed by a feed-forward neural network. This design enables the model to effectively process sequential data by attending to important contextual information.
Training Methodology:
The GPT model is pre-trained on a large corpus of text data, typically sourced from the internet, using an unsupervised learning approach. During pre-training, the model learns to predict the next word in a sentence given the preceding context, effectively capturing the statistical and semantic information from the text. The training process uses a variant of the Transformer's attention mechanism called the masked self-attention, which ensures that the model attends only to the previous words.
Fine-Tuning and Transfer Learning:
After pre-training, GPT undergoes a fine-tuning process on specific downstream NLP tasks. This involves training the model on domain-specific labeled data to learn task-specific patterns and improve performance. The general-purpose language model pre-trained on a large dataset allows GPT to transfer its knowledge to various NLP tasks, thus reducing the need for extensive task-specific training.
Performance and Applications:
GPT has achieved state-of-the-art performance on several benchmark NLP tasks, including language generation, summarization, translation, and rnn sentiment analysis. Its ability to generate coherent and contextually appropriate text has revolutionized various applications, such as chatbots, text completion, and question-answering systems. GPT's versatility across different domains and languages has made it a preferred choice for NLP researchers and practitioners.
Limitations and Future Directions:
Despite its immense success, GPT has certain limitations. One major limitation is its potential to generate biased or untruthful content if provided with biased training data. Addressing this issue and ensuring fairness in the generated text remains a critical focus of future research. Additionally, GPT's reliance on large amounts of training data and computational resources makes it less accessible for smaller organizations or researchers with limited resources.
Conclusion:
Generative Pre-Trained Transformer (GPT) has emerged as a powerful tool for natural language processing tasks. Its ability to leverage the Transformer model's attention mechanisms and transfer learning capabilities has resulted in impressive performance across a wide range of NLP applications. With ongoing research to address limitations such as bias and improved efficiency, GPT is expected to contribute significantly to the advancement of NLP and foster new breakthroughs in artificial intelligence.
댓글목록
등록된 댓글이 없습니다.