What Everyone seems to Be Saying About Deepseek Is Dead Wrong And Why
페이지 정보
작성자 Valentina 작성일25-02-15 11:43 조회3회 댓글0건관련링크
본문
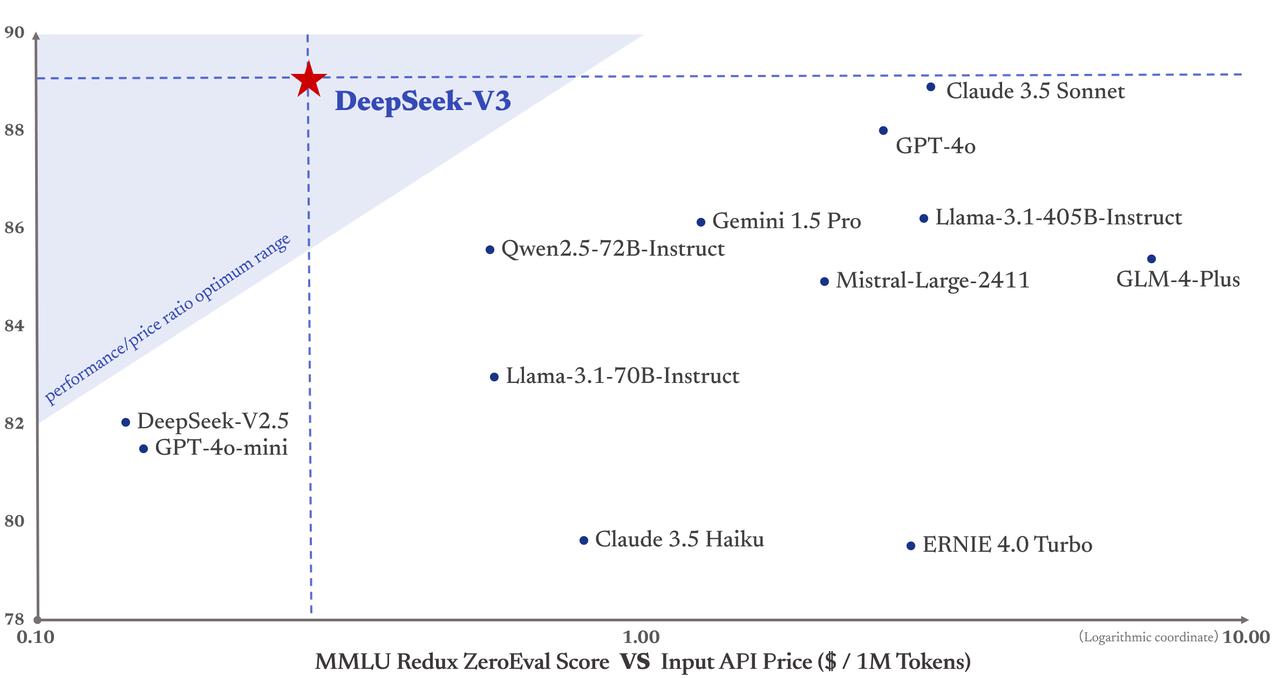 Setting aside the numerous irony of this claim, it's completely true that DeepSeek incorporated training data from OpenAI's o1 "reasoning" mannequin, and certainly, this is clearly disclosed within the analysis paper that accompanied DeepSeek's launch. Specifically, on AIME, MATH-500, and CNMO 2024, DeepSeek-V3 outperforms the second-greatest model, Qwen2.5 72B, by roughly 10% in absolute scores, which is a substantial margin for such challenging benchmarks. Just earlier than DeepSeek released its expertise, OpenAI had unveiled a brand new system, referred to as OpenAI o3, which seemed extra powerful than DeepSeek-V3. Conventional knowledge holds that giant language models like ChatGPT and DeepSeek have to be trained on increasingly more excessive-quality, human-created textual content to enhance; DeepSeek took one other method. It stays to be seen if this strategy will hold up lengthy-time period, or if its greatest use is coaching a equally-performing model with greater efficiency. Already, others are replicating the high-performance, low-value coaching strategy of DeepSeek. There are at present no accepted non-programmer options for using non-public data (ie sensitive, inner, or extremely sensitive data) with DeepSeek. Compressor summary: Key points: - The paper proposes a brand new object tracking task using unaligned neuromorphic and visible cameras - It introduces a dataset (CRSOT) with high-definition RGB-Event video pairs collected with a specifically built data acquisition system - It develops a novel tracking framework that fuses RGB and Event options utilizing ViT, uncertainty notion, and modality fusion modules - The tracker achieves strong tracking without strict alignment between modalities Summary: The paper presents a brand new object monitoring task with unaligned neuromorphic and visual cameras, a large dataset (CRSOT) collected with a custom system, and a novel framework that fuses RGB and Event options for strong monitoring without alignment.
Setting aside the numerous irony of this claim, it's completely true that DeepSeek incorporated training data from OpenAI's o1 "reasoning" mannequin, and certainly, this is clearly disclosed within the analysis paper that accompanied DeepSeek's launch. Specifically, on AIME, MATH-500, and CNMO 2024, DeepSeek-V3 outperforms the second-greatest model, Qwen2.5 72B, by roughly 10% in absolute scores, which is a substantial margin for such challenging benchmarks. Just earlier than DeepSeek released its expertise, OpenAI had unveiled a brand new system, referred to as OpenAI o3, which seemed extra powerful than DeepSeek-V3. Conventional knowledge holds that giant language models like ChatGPT and DeepSeek have to be trained on increasingly more excessive-quality, human-created textual content to enhance; DeepSeek took one other method. It stays to be seen if this strategy will hold up lengthy-time period, or if its greatest use is coaching a equally-performing model with greater efficiency. Already, others are replicating the high-performance, low-value coaching strategy of DeepSeek. There are at present no accepted non-programmer options for using non-public data (ie sensitive, inner, or extremely sensitive data) with DeepSeek. Compressor summary: Key points: - The paper proposes a brand new object tracking task using unaligned neuromorphic and visible cameras - It introduces a dataset (CRSOT) with high-definition RGB-Event video pairs collected with a specifically built data acquisition system - It develops a novel tracking framework that fuses RGB and Event options utilizing ViT, uncertainty notion, and modality fusion modules - The tracker achieves strong tracking without strict alignment between modalities Summary: The paper presents a brand new object monitoring task with unaligned neuromorphic and visual cameras, a large dataset (CRSOT) collected with a custom system, and a novel framework that fuses RGB and Event options for strong monitoring without alignment.
 DeepSeek is a sophisticated open-supply Large Language Model (LLM). Although giant-scale pretrained language fashions, reminiscent of BERT and RoBERTa, have achieved superhuman efficiency on in-distribution take a look at units, their performance suffers on out-of-distribution take a look at sets (e.g., on distinction units). Moreover, in the FIM completion activity, the DS-FIM-Eval inside test set showed a 5.1% enchancment, enhancing the plugin completion expertise. Further, fascinated builders also can check Codestral’s capabilities by chatting with an instructed version of the mannequin on Le Chat, Mistral’s free conversational interface. To know this, first it's good to know that AI model prices could be divided into two classes: coaching costs (a one-time expenditure to create the model) and runtime "inference" costs - the price of chatting with the model. Similarly, inference prices hover somewhere round 1/50th of the costs of the comparable Claude 3.5 Sonnet mannequin from Anthropic. Don't use this mannequin in providers made obtainable to finish customers.
DeepSeek is a sophisticated open-supply Large Language Model (LLM). Although giant-scale pretrained language fashions, reminiscent of BERT and RoBERTa, have achieved superhuman efficiency on in-distribution take a look at units, their performance suffers on out-of-distribution take a look at sets (e.g., on distinction units). Moreover, in the FIM completion activity, the DS-FIM-Eval inside test set showed a 5.1% enchancment, enhancing the plugin completion expertise. Further, fascinated builders also can check Codestral’s capabilities by chatting with an instructed version of the mannequin on Le Chat, Mistral’s free conversational interface. To know this, first it's good to know that AI model prices could be divided into two classes: coaching costs (a one-time expenditure to create the model) and runtime "inference" costs - the price of chatting with the model. Similarly, inference prices hover somewhere round 1/50th of the costs of the comparable Claude 3.5 Sonnet mannequin from Anthropic. Don't use this mannequin in providers made obtainable to finish customers.
By examining their sensible purposes, we’ll enable you perceive which mannequin delivers higher results in everyday tasks and business use instances. The final results have been optimized for helpfulness, while both reasoning chains and results were tuned for safety. The praise for DeepSeek-V2.5 follows a still ongoing controversy round HyperWrite’s Reflection 70B, which co-founder and CEO Matt Shumer claimed on September 5 was the "the world’s prime open-source AI mannequin," based on his inner benchmarks, only to see those claims challenged by impartial researchers and the wider AI analysis neighborhood, who have up to now didn't reproduce the said outcomes. Those concerned with the geopolitical implications of a Chinese company advancing in AI ought to really feel encouraged: researchers and corporations all over the world are rapidly absorbing and incorporating the breakthroughs made by DeepSeek. The availability of AI fashions below an MIT license promotes a growth type based mostly on a group-driven approach, allowing researchers and builders to work collectively and easily come up with new ideas. The GTX 1660 or 2060, AMD 5700 XT, or RTX 3050 or 3060 would all work nicely. Because the models are open-supply, anybody is able to totally inspect how they work and even create new fashions derived from DeepSeek.
The prices are presently excessive, but organizations like DeepSeek are slicing them down by the day. DeepSeek has finished each at much lower costs than the most recent US-made models. These charges are notably decrease than many rivals, making DeepSeek a gorgeous possibility for cost-acutely aware developers and companies. Many folks are involved about the energy demands and related environmental impact of AI coaching and inference, and it's heartening to see a improvement that could lead to more ubiquitous AI capabilities with a a lot decrease footprint. DeepSeek fashions and their derivatives are all accessible for public obtain on Hugging Face, a outstanding site for sharing AI/ML models. In the case of DeepSeek, sure biased responses are intentionally baked right into the model: for example, it refuses to have interaction in any discussion of Tiananmen Square or different, trendy controversies associated to the Chinese authorities. All AI fashions have the potential for bias in their generated responses. It additionally calls into query the overall "cheap" narrative of DeepSeek, when it couldn't have been achieved without the prior expense and energy of OpenAI. DeepSeek's high-efficiency, low-cost reveal calls into query the necessity of such tremendously high greenback investments; if state-of-the-art AI might be achieved with far fewer assets, is that this spending obligatory?
If you have any questions relating to where by and how to use Deepseek Online chat (sites.google.com), you can get in touch with us at our own web site.
댓글목록
등록된 댓글이 없습니다.