Mixture Of Experts
페이지 정보
작성자 Kai 작성일25-03-02 05:05 조회2회 댓글0건관련링크
본문
So no, you can’t replicate Free DeepSeek v3 the corporate for $5.576 million. While the enormous Open AI mannequin o1 fees $15 per million tokens. DeepSeek claimed the mannequin training took 2,788 thousand H800 GPU hours, which, at a cost of $2/GPU hour, comes out to a mere $5.576 million. The business is taking the company at its phrase that the price was so low. But DeepSeek has called into question that notion, and threatened the aura of invincibility surrounding America’s know-how industry. Let's revisit your comparison query on Friday. Finally, inference value for reasoning models is a tricky matter. DeepSeek, nonetheless, simply demonstrated that one other route is on the market: heavy optimization can produce exceptional outcomes on weaker hardware and with lower memory bandwidth; merely paying Nvidia more isn’t the only technique to make better models. Google, meanwhile, might be in worse form: a world of decreased hardware requirements lessens the relative benefit they've from TPUs.
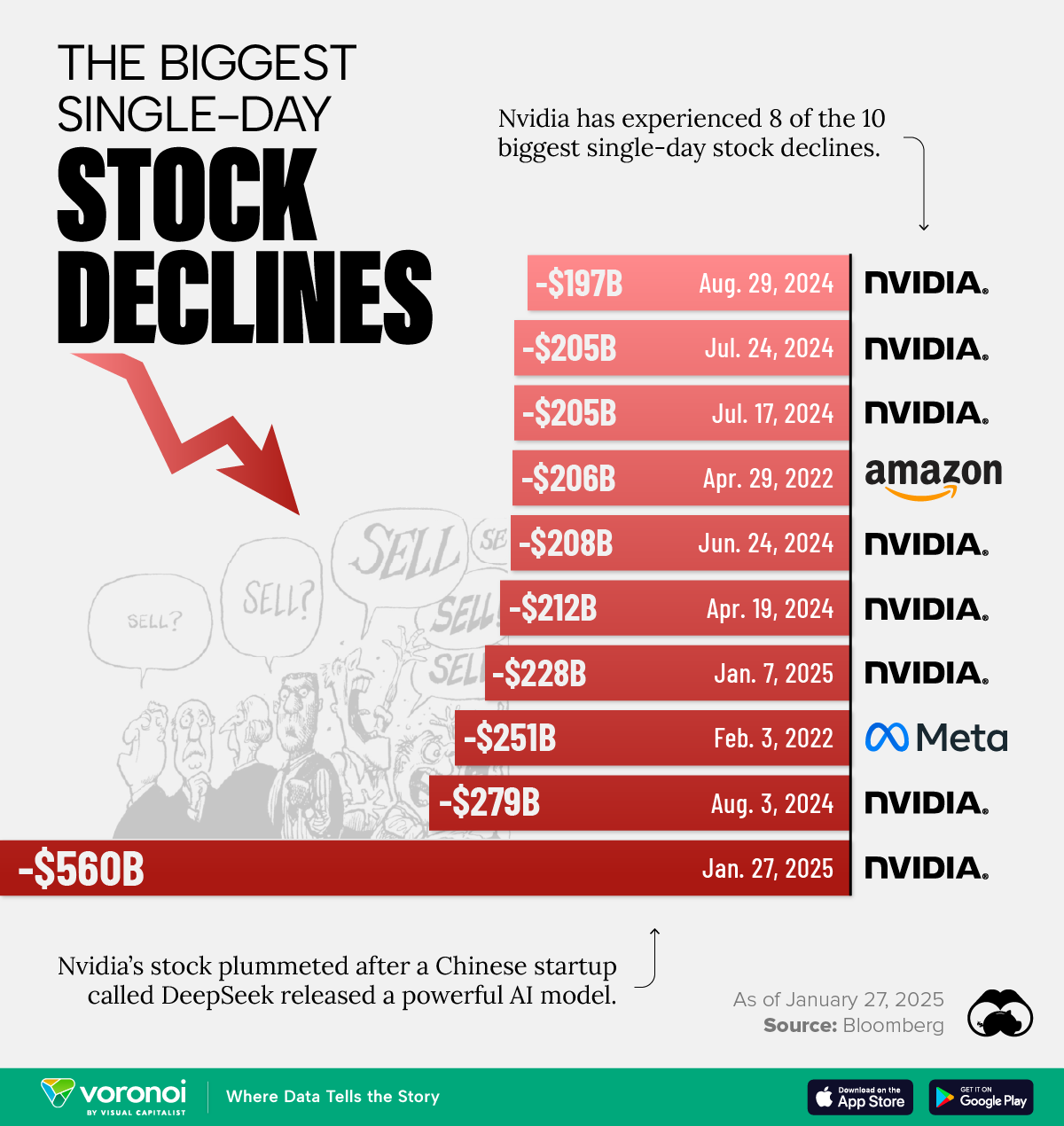 Improved Code Generation: The system's code technology capabilities have been expanded, permitting it to create new code more successfully and with greater coherence and performance. This ensures that customers with excessive computational calls for can still leverage the mannequin's capabilities effectively. It hasn’t yet proven it can handle a number of the massively formidable AI capabilities for industries that - for now - still require large infrastructure investments. In line with the synthetic evaluation quality index, Deepseek Online chat R1 is now second only to OpenAI’s o1 mannequin in overall high quality, beating leading models from Google, Meta, and Anthropic. First, there is the shock that China has caught as much as the main U.S. My image is of the long run; at present is the brief run, and it seems probably the market is working by way of the shock of R1’s existence. I requested why the stock costs are down; you just painted a positive image! Let’s work backwards: what was the V2 model, and why was it essential? Why haven’t you written about DeepSeek but? The discharge and recognition of the brand new DeepSeek mannequin caused huge disruptions in the Wall Street of the US.
Improved Code Generation: The system's code technology capabilities have been expanded, permitting it to create new code more successfully and with greater coherence and performance. This ensures that customers with excessive computational calls for can still leverage the mannequin's capabilities effectively. It hasn’t yet proven it can handle a number of the massively formidable AI capabilities for industries that - for now - still require large infrastructure investments. In line with the synthetic evaluation quality index, Deepseek Online chat R1 is now second only to OpenAI’s o1 mannequin in overall high quality, beating leading models from Google, Meta, and Anthropic. First, there is the shock that China has caught as much as the main U.S. My image is of the long run; at present is the brief run, and it seems probably the market is working by way of the shock of R1’s existence. I requested why the stock costs are down; you just painted a positive image! Let’s work backwards: what was the V2 model, and why was it essential? Why haven’t you written about DeepSeek but? The discharge and recognition of the brand new DeepSeek mannequin caused huge disruptions in the Wall Street of the US.
 Moreover, lots of the breakthroughs that undergirded V3 have been actually revealed with the release of the V2 model last January. I get the sense that one thing similar has occurred during the last 72 hours: the main points of what DeepSeek has achieved - and what they haven't - are much less essential than the response and what that response says about people’s pre-existing assumptions. How can I get support or ask questions on Deepseek Online chat Coder? DeepSeek Coder is a series of 8 models, four pretrained (Base) and four instruction-finetuned (Instruct). Distillation is easier for an organization to do on its own fashions, as a result of they've full entry, but you'll be able to still do distillation in a somewhat extra unwieldy approach by way of API, or even, should you get artistic, by way of chat clients. That, though, is itself an essential takeaway: we have now a scenario where AI fashions are educating AI models, and where AI fashions are teaching themselves. I noted above that if DeepSeek had access to H100s they probably would have used a larger cluster to train their mannequin, just because that would have been the simpler choice; the actual fact they didn’t, and were bandwidth constrained, drove a whole lot of their selections in terms of both model structure and their coaching infrastructure.
Moreover, lots of the breakthroughs that undergirded V3 have been actually revealed with the release of the V2 model last January. I get the sense that one thing similar has occurred during the last 72 hours: the main points of what DeepSeek has achieved - and what they haven't - are much less essential than the response and what that response says about people’s pre-existing assumptions. How can I get support or ask questions on Deepseek Online chat Coder? DeepSeek Coder is a series of 8 models, four pretrained (Base) and four instruction-finetuned (Instruct). Distillation is easier for an organization to do on its own fashions, as a result of they've full entry, but you'll be able to still do distillation in a somewhat extra unwieldy approach by way of API, or even, should you get artistic, by way of chat clients. That, though, is itself an essential takeaway: we have now a scenario where AI fashions are educating AI models, and where AI fashions are teaching themselves. I noted above that if DeepSeek had access to H100s they probably would have used a larger cluster to train their mannequin, just because that would have been the simpler choice; the actual fact they didn’t, and were bandwidth constrained, drove a whole lot of their selections in terms of both model structure and their coaching infrastructure.
Actually, the burden of proof is on the doubters, at least once you understand the V3 architecture. Xin believes that whereas LLMs have the potential to speed up the adoption of formal arithmetic, their effectiveness is proscribed by the availability of handcrafted formal proof knowledge. Additionally, the paper does not handle the potential generalization of the GRPO method to different forms of reasoning duties past arithmetic. The "aha moment" serves as a robust reminder of the potential of RL to unlock new levels of intelligence in synthetic systems, paving the best way for extra autonomous and adaptive models sooner or later. Well, almost: R1-Zero reasons, however in a means that humans have bother understanding. The dramatic expansion in the chip ban that culminated in the Biden administration reworking chip sales to a permission-primarily based structure was downstream from people not understanding the intricacies of chip manufacturing, and being completely blindsided by the Huawei Mate 60 Pro. So was this a violation of the chip ban? Nope. H100s had been prohibited by the chip ban, however not H800s. Here’s the thing: a huge variety of the improvements I explained above are about overcoming the lack of reminiscence bandwidth implied in utilizing H800s instead of H100s.
댓글목록
등록된 댓글이 없습니다.